In statistics, a ranklet is an orientation-selective non-parametric feature which is based on the computation of Mann–Whitney–Wilcoxon (MWW) rank-sum test statistics.[1] Ranklets achieve similar response to Haar wavelets as they share the same pattern of orientation-selectivity, multi-scale nature and a suitable notion of completeness.[2] There were invented by Fabrizio Smeralhi in 2002.
Rank-based (non-parametric) features have become popular in the field of image processing for their robustness in detecting outliers and invariance to monotonic transformations such as brightness, contrast changes and gamma correction.
The MWW is a combination of Wilcoxon rank-sum test and Mann–Whitney U-test. It is a non-parametric alternative to the t-test used to test the hypothesis for the comparison of two independent distributions. It assesses whether two samples of observations, usually referred as Treatment T and Control C, come from the same distribution but do not have to be normally distributed.
The Wilcoxon rank-sum statistics Ws is determined as:[3]
![W_{s}=\sum _{{i=1}}^{N}\pi _{i}V_{i}{\text{ where }}\pi _{i}={\text{rank of element }}i{\text{ and }}V_{i}={\begin{cases}0&{\text{ for }}\pi _{i}\in C\\[3pt]1&{\text{ for }}\pi _{i}\in T\end{cases}}](../I/d977d9136b0ffd5009f33241851f3f4075dd6feb.svg)
Subsequently, let MW be the Mann–Whitney statistics defined by:

where m is the number of Treatment values.
A ranklet R is defined as the normalization of MW in the range [−1, +1]:

where a positive value means that the Treatment region is brighter than the Control region, and a negative value otherwise.
Example
Suppose and then


| Intensity | 1 | 4 | 5 | 7 | 9 | 10 | 11 | 13 | 15 | 19 | 20 |
| Sample | T | C | T | C | T | T | C | C | T | C | C |
| Rank | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |

![MW=24-[5\times (5+1)/2]=9](../I/5d42c6d7b62af7e63de38f07b6e3b2b9690ee676.svg)
![R=[9/[5\times 6/2]]-1=-0.4](../I/5c246e039e3aa9db4bfc6e64ac0e91e84844f4e1.svg)
Hence, in the above example the Control region was a little bit brighter than the Treatment region.
Method
Since Ranklets are non-linear filters, they can only be applied in the spatial domain. Filtering with Ranklets involves dividing an image window W into Treatment and Control regions as shown in the image below:
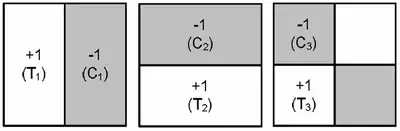
Subsequently, Wilcoxon rank-sum test statistics are computed in order to determine the intensity variations among conveniently chosen regions (according to the required orientation) of the samples in W. The intensity values of both regions are then replaced by the respective ranking scores. These ranking scores determine a pairwise comparison between the T and C regions. This means that a ranklet essentially counts the number of TxC pairs which are brighter in the T set. Hence a positive value means that the Treatment values are brighter than the Control values, and vice versa.
References
- ↑ "www.Ranklets.net". www.eecs.qmul.ac.uk. Retrieved 2022-06-05.
- ↑ Smeraldi, F. (August 2002). "Ranklets: Orientation selective non-parametric features applied to face detection". Object recognition supported by user interaction for service robots. Vol. 3. pp. 379–382. doi:10.1109/ICPR.2002.1047924. S2CID 16667804.
- ↑ "www.Ranklets.net". www.eecs.qmul.ac.uk. Retrieved 2022-06-05.