
StyleGAN is a generative adversarial network (GAN) introduced by Nvidia researchers in December 2018,[1] and made source available in February 2019.[2][3]
StyleGAN depends on Nvidia's CUDA software, GPUs, and Google's TensorFlow,[4] or Meta AI's PyTorch, which supersedes TensorFlow as the official implementation library in later StyleGAN versions.[5] The second version of StyleGAN, called StyleGAN2, was published on February 5, 2020. It removes some of the characteristic artifacts and improves the image quality.[6][7] Nvidia introduced StyleGAN3, described as an "alias-free" version, on June 23, 2021, and made source available on October 12, 2021.[8]
History
A direct predecessor of the StyleGAN series is the Progressive GAN, published in 2017.[9]
In December 2018, Nvidia researchers distributed a preprint with accompanying software introducing StyleGAN, a GAN for producing an unlimited number of (often convincing) portraits of fake human faces. StyleGAN was able to run on Nvidia's commodity GPU processors.
In February 2019, Uber engineer Phillip Wang used the software to create This Person Does Not Exist, which displayed a new face on each web page reload.[10][11] Wang himself has expressed amazement, given that humans are evolved to specifically understand human faces, that nevertheless StyleGAN can competitively "pick apart all the relevant features (of human faces) and recompose them in a way that's coherent."[12]
In September 2019, a website called Generated Photos published 100,000 images as a collection of stock photos.[13] The collection was made using a private dataset shot in a controlled environment with similar light and angles.[14]
Similarly, two faculty at the University of Washington's Information School used StyleGAN to create Which Face is Real?, which challenged visitors to differentiate between a fake and a real face side by side.[11] The faculty stated the intention was to "educate the public" about the existence of this technology so they could be wary of it, "just like eventually most people were made aware that you can Photoshop an image".[15]
The second version of StyleGAN, called StyleGAN2, was published on February 5, 2020. It removes some of the characteristic artifacts and improves the image quality.[6][7]
In 2021, a third version was released, improving consistency between fine and coarse details in the generator. Dubbed "alias-free", this version was implemented with pytorch.[16]
Illicit use
In December 2019, Facebook took down a network of accounts with false identities, and mentioned that some of them had used profile pictures created with artificial intelligence.[17]
Architecture
Progressive GAN
Progressive GAN[9] is a method for training GAN for large-scale image generation stably, by growing a GAN generator from small to large scale in a pyramidal fashion. Like SinGAN, it decomposes the generator as , and the discriminator as .


During training, at first only are used in a GAN game to generate 4x4 images. Then are added to reach the second stage of GAN game, to generate 8x8 images, and so on, until we reach a GAN game to generate 1024x1024 images.


To avoid discontinuity between stages of the GAN game, each new layer is "blended in" (Figure 2 of the paper[9]). For example, this is how the second stage GAN game starts:
- Just before, the GAN game consists of the pair generating and discriminating 4x4 images.
- Just after, the GAN game consists of the pair generating and discriminating 8x8 images. Here, the functions are image up- and down-sampling functions, and is a blend-in factor (much like an alpha in image composing) that smoothly glides from 0 to 1.



StyleGAN
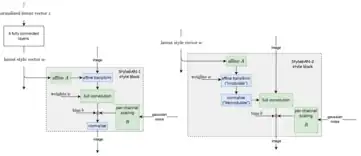
StyleGAN is designed as a combination of Progressive GAN with neural style transfer.[18]
The key architectural choice of StyleGAN-1 is a progressive growth mechanism, similar to Progressive GAN. Each generated image starts as a constant[note 1] array, and repeatedly passed through style blocks. Each style block applies a "style latent vector" via affine transform ("adaptive instance normalization"), similar to how neural style transfer uses Gramian matrix. It then adds noise, and normalize (subtract the mean, then divide by the variance).

At training time, usually only one style latent vector is used per image generated, but sometimes two ("mixing regularization") in order to encourage each style block to independently perform its stylization without expecting help from other style blocks (since they might receive an entirely different style latent vector).
After training, multiple style latent vectors can be fed into each style block. Those fed to the lower layers control the large-scale styles, and those fed to the higher layers control the fine-detail styles.
Style-mixing between two images can be performed as well. First, run a gradient descent to find such that . This is called "projecting an image back to style latent space". Then, can be fed to the lower style blocks, and to the higher style blocks, to generate a composite image that has the large-scale style of , and the fine-detail style of . Multiple images can also be composed this way.







StyleGAN2
StyleGAN2 improves upon StyleGAN in two ways.
One, it applies the style latent vector to transform the convolution layer's weights instead, thus solving the "blob" problem.[19] The "blob" problem roughly speaking is because using the style latent vector to normalize the generated image destroys useful information. Consequently, the generator learned to create a "distraction" by a large blob, which absorbs most of the effect of normalization (somewhat similar to using flares to distract a heat-seeking missile).
Two, it uses residual connections, which helps it avoid the phenomenon where certain features are stuck at intervals of pixels. For example, the seam between two teeth may be stuck at pixels divisible by 32, because the generator learned to generate teeth during stage N-5, and consequently could only generate primitive teeth at that stage, before scaling up 5 times (thus intervals of 32).
This was updated by the StyleGAN2-ADA ("ADA" stands for "adaptive"),[20] which uses invertible data augmentation. It also tunes the amount of data augmentation applied by starting at zero, and gradually increasing it until an "overfitting heuristic" reaches a target level, thus the name "adaptive".
StyleGAN3
StyleGAN3[21] improves upon StyleGAN2 by solving the "texture sticking" problem, which can be seen in the official videos.[22] They analyzed the problem by the Nyquist–Shannon sampling theorem, and argued that the layers in the generator learned to exploit the high-frequency signal in the pixels they operate upon.
To solve this, they proposed imposing strict lowpass filters between each generator's layers, so that the generator is forced to operate on the pixels in a way faithful to the continuous signals they represent, rather than operate on them as merely discrete signals. They further imposed rotational and translational invariance by using more signal filters. The resulting StyleGAN-3 is able to generate images that rotate and translate smoothly, and without texture sticking.
See also
Notes
- ↑ It is learned during the training, but afterwards it is held constant, much like a bias vector.
References
- ↑ "GAN 2.0: NVIDIA's Hyperrealistic Face Generator". SyncedReview.com. December 14, 2018. Retrieved October 3, 2019.
- ↑ "NVIDIA Open-Sources Hyper-Realistic Face Generator StyleGAN". Medium.com. February 9, 2019. Retrieved October 3, 2019.
- ↑ Beschizza, Rob (February 15, 2019). "This Person Does Not Exist". Boing-Boing. Retrieved February 16, 2019.
- ↑ Larabel, Michael (February 10, 2019). "NVIDIA Opens Up The Code To StyleGAN - Create Your Own AI Family Portraits". Phoronix.com. Retrieved October 3, 2019.
- ↑ "Looking for the PyTorch version? - Stylegan2". github.com. October 28, 2021. Retrieved August 5, 2022.
- 1 2 "Synthesizing High-Resolution Images with StyleGAN2 – NVIDIA Developer News Center". news.developer.nvidia.com. June 17, 2020. Retrieved August 11, 2020.
- 1 2 NVlabs/stylegan2, NVIDIA Research Projects, August 11, 2020, retrieved August 11, 2020
- ↑ Kakkar, Shobha (October 13, 2021). "NVIDIA AI Releases StyleGAN3: Alias-Free Generative Adversarial Networks". MarkTechPost. Retrieved October 14, 2021.
- 1 2 3 Karras, Tero; Aila, Timo; Laine, Samuli; Lehtinen, Jaakko (2018). "Progressive Growing of GANs for Improved Quality, Stability, and Variation". International Conference on Learning Representations. arXiv:1710.10196.
- ↑ msmash, n/a (February 14, 2019). "'This Person Does Not Exist' Website Uses AI To Create Realistic Yet Horrifying Faces". Slashdot. Retrieved February 16, 2019.
- 1 2 Fleishman, Glenn (April 30, 2019). "How to spot the realistic fake people creeping into your timelines". Fast Company. Retrieved June 7, 2020.
- ↑ Bishop, Katie (February 7, 2020). "AI in the adult industry: porn may soon feature people who don't exist". The Guardian. Retrieved June 8, 2020.
- ↑ Porter, Jon (September 20, 2019). "100,000 free AI-generated headshots put stock photo companies on notice". The Verge. Retrieved August 4, 2020.
- ↑ Timmins, Jane Wakefield and Beth (February 29, 2020). "Could deepfakes be used to train office workers?". BBC News. Retrieved August 4, 2020.
- ↑ Vincent, James (March 3, 2019). "Can you tell the difference between a real face and an AI-generated fake?". The Verge. Retrieved June 8, 2020.
- ↑ NVlabs/stylegan3, NVIDIA Research Projects, October 11, 2021
- ↑ "Facebook's latest takedown has a twist -- AI-generated profile pictures". ABC News. Retrieved August 4, 2020.
- ↑ Karras, Tero; Laine, Samuli; Aila, Timo (2019). "A Style-Based Generator Architecture for Generative Adversarial Networks" (PDF). 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE. pp. 4396–4405. arXiv:1812.04948. doi:10.1109/CVPR.2019.00453. ISBN 978-1-7281-3293-8. S2CID 54482423.
- ↑ Karras, Tero; Laine, Samuli; Aittala, Miika; Hellsten, Janne; Lehtinen, Jaakko; Aila, Timo (2020). "Analyzing and Improving the Image Quality of StyleGAN" (PDF). 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE. pp. 8107–8116. arXiv:1912.04958. doi:10.1109/CVPR42600.2020.00813. ISBN 978-1-7281-7168-5. S2CID 209202273.
- ↑ Tero, Karras; Miika, Aittala; Janne, Hellsten; Samuli, Laine; Jaakko, Lehtinen; Timo, Aila (2020). "Training Generative Adversarial Networks with Limited Data". Advances in Neural Information Processing Systems. 33.
- ↑ Karras, Tero; Aittala, Miika; Laine, Samuli; Härkönen, Erik; Hellsten, Janne; Lehtinen, Jaakko; Aila, Timo (2021). Alias-Free Generative Adversarial Networks (PDF). Advances in Neural Information Processing Systems.
- ↑ Karras, Tero; Aittala, Miika; Laine, Samuli; Härkönen, Erik; Hellsten, Janne; Lehtinen, Jaakko; Aila, Timo. "Alias-Free Generative Adversarial Networks (StyleGAN3)". nvlabs.github.io. Retrieved July 16, 2022.